 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Face Anti-spoofing
Papers and Code
LitMAS: A Lightweight and Generalized Multi-Modal Anti-Spoofing Framework for Biometric Security
Jun 07, 2025Biometric authentication systems are increasingly being deployed in critical applications, but they remain susceptible to spoofing. Since most of the research efforts focus on modality-specific anti-spoofing techniques, building a unified, resource-efficient solution across multiple biometric modalities remains a challenge. To address this, we propose LitMAS, a $\textbf{Li}$gh$\textbf{t}$ weight and generalizable $\textbf{M}$ulti-modal $\textbf{A}$nti-$\textbf{S}$poofing framework designed to detect spoofing attacks in speech, face, iris, and fingerprint-based biometric systems. At the core of LitMAS is a Modality-Aligned Concentration Loss, which enhances inter-class separability while preserving cross-modal consistency and enabling robust spoof detection across diverse biometric traits. With just 6M parameters, LitMAS surpasses state-of-the-art methods by $1.36\%$ in average EER across seven datasets, demonstrating high efficiency, strong generalizability, and suitability for edge deployment. Code and trained models are available at https://github.com/IAB-IITJ/LitMAS.
Generative Classifier for Domain Generalization
Apr 03, 2025Domain generalization (DG) aims to improve the generalizability of computer vision models toward distribution shifts. The mainstream DG methods focus on learning domain invariance, however, such methods overlook the potential inherent in domain-specific information. While the prevailing practice of discriminative linear classifier has been tailored to domain-invariant features, it struggles when confronted with diverse domain-specific information, e.g., intra-class shifts, that exhibits multi-modality. To address these issues, we explore the theoretical implications of relying on domain invariance, revealing the crucial role of domain-specific information in mitigating the target risk for DG. Drawing from these insights, we propose Generative Classifier-driven Domain Generalization (GCDG), introducing a generative paradigm for the DG classifier based on Gaussian Mixture Models (GMMs) for each class across domains. GCDG consists of three key modules: Heterogeneity Learning Classifier~(HLC), Spurious Correlation Blocking~(SCB), and Diverse Component Balancing~(DCB). Concretely, HLC attempts to model the feature distributions and thereby capture valuable domain-specific information via GMMs. SCB identifies the neural units containing spurious correlations and perturbs them, mitigating the risk of HLC learning spurious patterns. Meanwhile, DCB ensures a balanced contribution of components in HLC, preventing the underestimation or neglect of critical components. In this way, GCDG excels in capturing the nuances of domain-specific information characterized by diverse distributions. GCDG demonstrates the potential to reduce the target risk and encourage flat minima, improving the generalizability. Extensive experiments show GCDG's comparable performance on five DG benchmarks and one face anti-spoofing dataset, seamlessly integrating into existing DG methods with consistent improvements.
A Multi-Modal Approach for Face Anti-Spoofing in Non-Calibrated Systems using Disparity Maps
Oct 31, 2024



Face recognition technologies are increasingly used in various applications, yet they are vulnerable to face spoofing attacks. These spoofing attacks often involve unique 3D structures, such as printed papers or mobile device screens. Although stereo-depth cameras can detect such attacks effectively, their high-cost limits their widespread adoption. Conversely, two-sensor systems without extrinsic calibration offer a cost-effective alternative but are unable to calculate depth using stereo techniques. In this work, we propose a method to overcome this challenge by leveraging facial attributes to derive disparity information and estimate relative depth for anti-spoofing purposes, using non-calibrated systems. We introduce a multi-modal anti-spoofing model, coined Disparity Model, that incorporates created disparity maps as a third modality alongside the two original sensor modalities. We demonstrate the effectiveness of the Disparity Model in countering various spoof attacks using a comprehensive dataset collected from the Intel RealSense ID Solution F455. Our method outperformed existing methods in the literature, achieving an Equal Error Rate (EER) of 1.71% and a False Negative Rate (FNR) of 2.77% at a False Positive Rate (FPR) of 1%. These errors are lower by 2.45% and 7.94% than the errors of the best comparison method, respectively. Additionally, we introduce a model ensemble that addresses 3D spoof attacks as well, achieving an EER of 2.04% and an FNR of 3.83% at an FPR of 1%. Overall, our work provides a state-of-the-art solution for the challenging task of anti-spoofing in non-calibrated systems that lack depth information.
Suppress and Rebalance: Towards Generalized Multi-Modal Face Anti-Spoofing
Mar 05, 2024



Face Anti-Spoofing (FAS) is crucial for securing face recognition systems against presentation attacks. With advancements in sensor manufacture and multi-modal learning techniques, many multi-modal FAS approaches have emerged. However, they face challenges in generalizing to unseen attacks and deployment conditions. These challenges arise from (1) modality unreliability, where some modality sensors like depth and infrared undergo significant domain shifts in varying environments, leading to the spread of unreliable information during cross-modal feature fusion, and (2) modality imbalance, where training overly relies on a dominant modality hinders the convergence of others, reducing effectiveness against attack types that are indistinguishable sorely using the dominant modality. To address modality unreliability, we propose the Uncertainty-Guided Cross-Adapter (U-Adapter) to recognize unreliably detected regions within each modality and suppress the impact of unreliable regions on other modalities. For modality imbalance, we propose a Rebalanced Modality Gradient Modulation (ReGrad) strategy to rebalance the convergence speed of all modalities by adaptively adjusting their gradients. Besides, we provide the first large-scale benchmark for evaluating multi-modal FAS performance under domain generalization scenarios. Extensive experiments demonstrate that our method outperforms state-of-the-art methods. Source code and protocols will be released on https://github.com/OMGGGGG/mmdg.
FaceCat: Enhancing Face Recognition Security with a Unified Generative Model Framework
Apr 14, 2024Face anti-spoofing (FAS) and adversarial detection (FAD) have been regarded as critical technologies to ensure the safety of face recognition systems. As a consequence of their limited practicality and generalization, some existing methods aim to devise a framework capable of concurrently detecting both threats to address the challenge. Nevertheless, these methods still encounter challenges of insufficient generalization and suboptimal robustness, potentially owing to the inherent drawback of discriminative models. Motivated by the rich structural and detailed features of face generative models, we propose FaceCat which utilizes the face generative model as a pre-trained model to improve the performance of FAS and FAD. Specifically, FaceCat elaborately designs a hierarchical fusion mechanism to capture rich face semantic features of the generative model. These features then serve as a robust foundation for a lightweight head, designed to execute FAS and FAD tasks simultaneously. As relying solely on single-modality data often leads to suboptimal performance, we further propose a novel text-guided multi-modal alignment strategy that utilizes text prompts to enrich feature representation, thereby enhancing performance. For fair evaluations, we build a comprehensive protocol with a wide range of 28 attack types to benchmark the performance. Extensive experiments validate the effectiveness of FaceCat generalizes significantly better and obtains excellent robustness against input transformations.
MA-ViT: Modality-Agnostic Vision Transformers for Face Anti-Spoofing
Apr 15, 2023The existing multi-modal face anti-spoofing (FAS) frameworks are designed based on two strategies: halfway and late fusion. However, the former requires test modalities consistent with the training input, which seriously limits its deployment scenarios. And the latter is built on multiple branches to process different modalities independently, which limits their use in applications with low memory or fast execution requirements. In this work, we present a single branch based Transformer framework, namely Modality-Agnostic Vision Transformer (MA-ViT), which aims to improve the performance of arbitrary modal attacks with the help of multi-modal data. Specifically, MA-ViT adopts the early fusion to aggregate all the available training modalities data and enables flexible testing of any given modal samples. Further, we develop the Modality-Agnostic Transformer Block (MATB) in MA-ViT, which consists of two stacked attentions named Modal-Disentangle Attention (MDA) and Cross-Modal Attention (CMA), to eliminate modality-related information for each modal sequences and supplement modality-agnostic liveness features from another modal sequences, respectively. Experiments demonstrate that the single model trained based on MA-ViT can not only flexibly evaluate different modal samples, but also outperforms existing single-modal frameworks by a large margin, and approaches the multi-modal frameworks introduced with smaller FLOPs and model parameters.
FM-ViT: Flexible Modal Vision Transformers for Face Anti-Spoofing
May 05, 2023The availability of handy multi-modal (i.e., RGB-D) sensors has brought about a surge of face anti-spoofing research. However, the current multi-modal face presentation attack detection (PAD) has two defects: (1) The framework based on multi-modal fusion requires providing modalities consistent with the training input, which seriously limits the deployment scenario. (2) The performance of ConvNet-based model on high fidelity datasets is increasingly limited. In this work, we present a pure transformer-based framework, dubbed the Flexible Modal Vision Transformer (FM-ViT), for face anti-spoofing to flexibly target any single-modal (i.e., RGB) attack scenarios with the help of available multi-modal data. Specifically, FM-ViT retains a specific branch for each modality to capture different modal information and introduces the Cross-Modal Transformer Block (CMTB), which consists of two cascaded attentions named Multi-headed Mutual-Attention (MMA) and Fusion-Attention (MFA) to guide each modal branch to mine potential features from informative patch tokens, and to learn modality-agnostic liveness features by enriching the modal information of own CLS token, respectively. Experiments demonstrate that the single model trained based on FM-ViT can not only flexibly evaluate different modal samples, but also outperforms existing single-modal frameworks by a large margin, and approaches the multi-modal frameworks introduced with smaller FLOPs and model parameters.
Learning Polysemantic Spoof Trace: A Multi-Modal Disentanglement Network for Face Anti-spoofing
Dec 07, 2022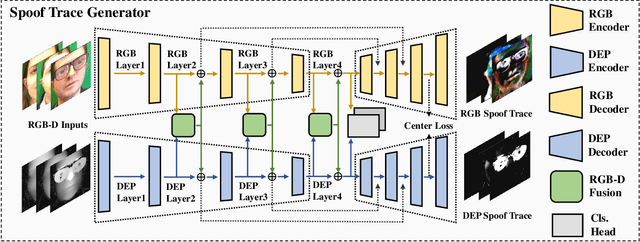
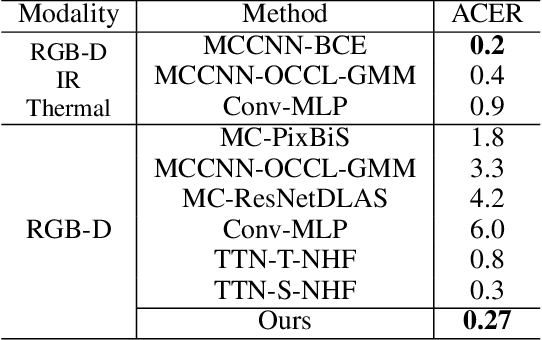
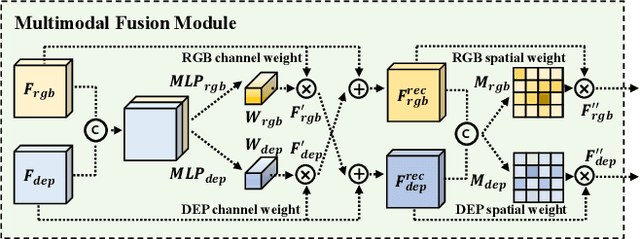
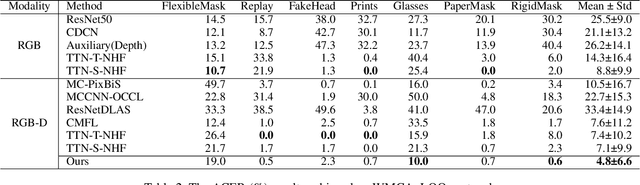
Along with the widespread use of face recognition systems, their vulnerability has become highlighted. While existing face anti-spoofing methods can be generalized between attack types, generic solutions are still challenging due to the diversity of spoof characteristics. Recently, the spoof trace disentanglement framework has shown great potential for coping with both seen and unseen spoof scenarios, but the performance is largely restricted by the single-modal input. This paper focuses on this issue and presents a multi-modal disentanglement model which targetedly learns polysemantic spoof traces for more accurate and robust generic attack detection. In particular, based on the adversarial learning mechanism, a two-stream disentangling network is designed to estimate spoof patterns from the RGB and depth inputs, respectively. In this case, it captures complementary spoofing clues inhering in different attacks. Furthermore, a fusion module is exploited, which recalibrates both representations at multiple stages to promote the disentanglement in each individual modality. It then performs cross-modality aggregation to deliver a more comprehensive spoof trace representation for prediction. Extensive evaluations are conducted on multiple benchmarks, demonstrating that learning polysemantic spoof traces favorably contributes to anti-spoofing with more perceptible and interpretable results.
Review of Face Presentation Attack Detection Competitions
Dec 21, 2021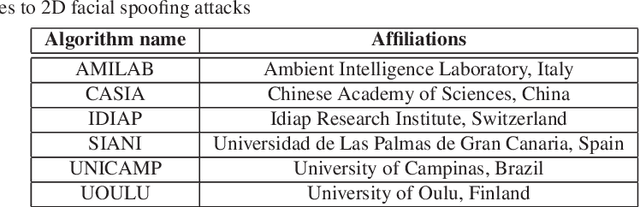

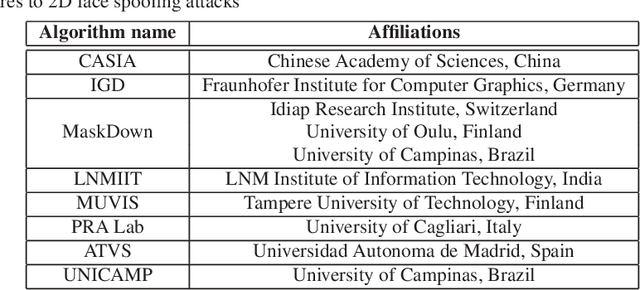

Face presentation attack detection (PAD) has received increasing attention ever since the vulnerabilities to spoofing have been widely recognized. The state of the art in unimodal and multi-modal face anti-spoofing has been assessed in eight international competitions organized in conjunction with major biometrics and computer vision conferences in 2011, 2013, 2017, 2019, 2020 and 2021, each introducing new challenges to the research community. In this chapter, we present the design and results of the five latest competitions from 2019 until 2021. The first two challenges aimed to evaluate the effectiveness of face PAD in multi-modal setup introducing near-infrared (NIR) and depth modalities in addition to colour camera data, while the latest three competitions focused on evaluating domain and attack type generalization abilities of face PAD algorithms operating on conventional colour images and videos. We also discuss the lessons learnt from the competitions and future challenges in the field in general.
A Dataset and Benchmark Towards Multi-Modal Face Anti-Spoofing Under Surveillance Scenarios
Mar 29, 2021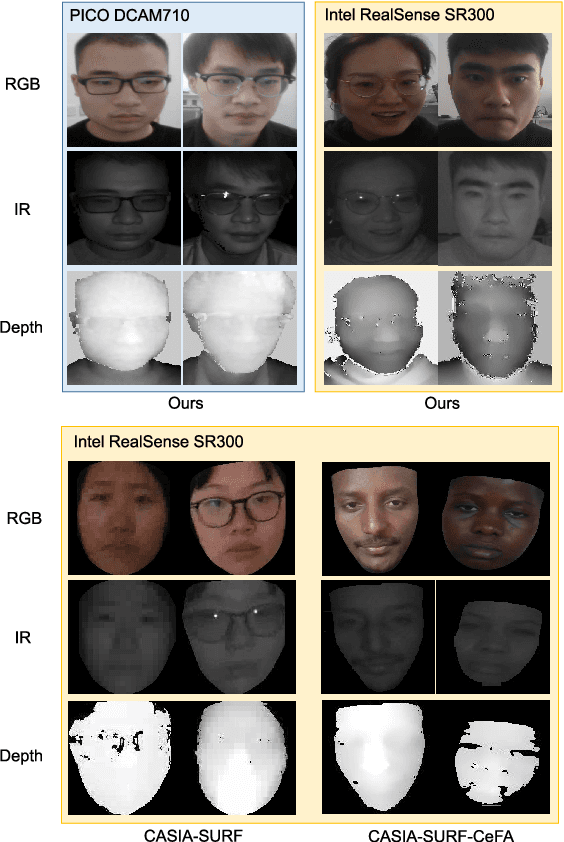
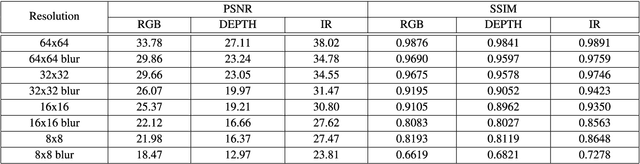

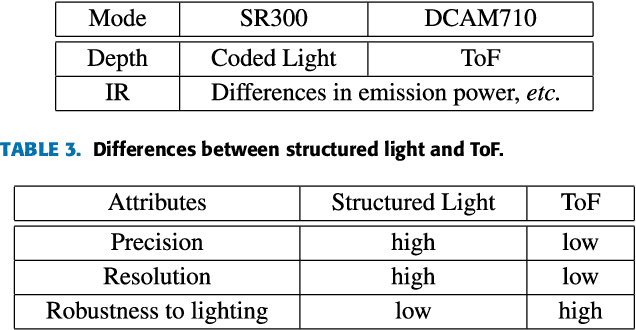
Face Anti-spoofing (FAS) is a challenging problem due to complex serving scenarios and diverse face presentation attack patterns. Especially when captured images are low-resolution, blurry, and coming from different domains, the performance of FAS will degrade significantly. The existing multi-modal FAS datasets rarely pay attention to the cross-domain problems under deployment scenarios, which is not conducive to the study of model performance. To solve these problems, we explore the fine-grained differences between multi-modal cameras and construct a cross-domain multi-modal FAS dataset under surveillance scenarios called GREAT-FASD-S. Besides, we propose an Attention based Face Anti-spoofing network with Feature Augment (AFA) to solve the FAS towards low-quality face images. It consists of the depthwise separable attention module (DAM) and the multi-modal based feature augment module (MFAM). Our model can achieve state-of-the-art performance on the CASIA-SURF dataset and our proposed GREAT-FASD-S dataset.
* Published in: IEEE Access